반응형
클러스터링(Clustering) 은 비지도학습(unsupervised learning)의 핵심 기법으로, 레이블(정답)이 없는 데이터에서 유사한 데이터 포인트들을 자동으로 여러 개의 그룹으로 묶는 과정입니다.
데이터 하나하나가 뭔지 알려주지 않고 그저 수많은 데이터를 컴퓨터에게 던져주면, 컴퓨터가 각 데이터에 내재된 구조나 패턴을 찾아내서 나름의 기준(유사성)으로 데이터들을 분류하여 여러 개의 그룹(클러스터)으로 나누는 것입니다.
클러스터링의 목표는 클러스터 내 유사성(intra-cluster similarity)을 최대화하고 클러스터 간 유사성(inter-cluster similarity)을 최소화하는 것입니다.
지도학습과의 관계
머신러닝의 지도학습(supervised learning) 관점에서 보면,
- 지도학습은 정답이 있는(labeled) 데이터로 예측 모델을 학습하여 새로운 데이터의 정답(label)을 예측하는 데 초점을 맞춥니다.
- 클러스터링은 데이터의 내재적 구조를 탐색하여 숨겨진 패턴을 발견하고 유사성에 따라 그룹화하는 것이 목적입니다.
- 클러스터링의 이러한 특징은 지도학습의 전처리 단계로 활용됩니다.
주요 알고리즘

- K-평균 (K-Means): 최적의 K 찾기
- 사용자가 미리 지정한 K개의 클러스터 중심(Centroid)을 기준으로, 각 데이터 포인트가 가장 가까운 중심에 할당되도록 반복적으로 중심을 이동시키며 클러스터를 형성합니다.
- 가장 단순하고 빠른 클러스터링 알고리즘입니다.
- 중심점을 이동시킬 때는 각 클러스터 안에 속한 모든 데이터의 산술평균 좌표로 옯깁니다.

- 계층적 클러스터링 (Hierarchical Clustering): 그룹 수 직접 정하기.
- 모든 고객을 처음엔 1명씩 따로 보고, 점점 가까운 사람들끼리 합쳐가면서 ‘가계도(덴드로그램)’를 만드는 방법입니다.
- 데이터를 나무 구조(Dendrogram)로 묶거나 나누면서 클러스터를 형성합니다.
- 비즈니스팀이 직접 원하는 그룹 수에 맞춰서 '원하는 높이' 에서 자르게 합니다.
- 활용 포인트
- 고객 수가 5만명 이하일 때
- 마케팅팀이 직접 그룹 수를 정하려고 할 때
- 계층 구조가 필요할 때
- K-means 실루엣 점수가 0.45 이하로 안좋을 때
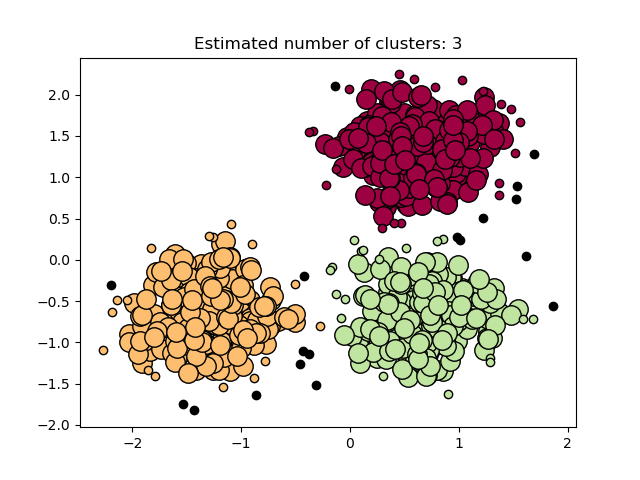
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise): 실무 최강 클러스터링
- 밀도(Density)를 기반으로 클러스터를 찾으며, 이상치(Outlier, Noise)를 잘 분리해냅니다.
- 데이터 포인트의 밀도가 높은 곳은 클러스터로 만들고, 밀도 낮은 곳은 노이즈(이상치)로 버리기 때문에, 이상치가 많은 실제 데이터에서 실루엣 점수 0.7 이상을 보장합니다.
- 핵심 파라미터
- eps: '이 거리 안에 있으면 친구'. 실무 기본값은 0.3 ~ 0.8
- min_samples: '최소 몇 명이어야 클러스터로 인정한다'. 실무 기본값은 5~20. (데이터 10만 건 기준 10)
알고리즘 비교
| 항목 | K-means | 계층적 클러스터링 | DBSCAN |
| 한 줄 요약 | 빠르고 해석 쉬운 국민 클러스터링 | 마케팅팀이 직접 그룹 수를 선택하는 고급 클러스터링 | 이상치 자동 제거/그룹의 모양이 자유로운 2025년 실무 최강 클러스터링 |
| K 정하기 | 꼭 미리 정해야 함 | 필요 없음 → 덴드로그램에서 자름 | 필요 없음 → 밀도로 자동 결정 |
| 클러스터 모양 | 무조건 동그랗게만 가능 | 동그라미~타원형 가능 | 어떤 모양이든 다 가능 (뱀, 반달, 도넛 등) |
| 이상치 처리 | 억지로 어딘가에 넣음 → 실루엣 점수 폭락 | 어느 정도 반영됨 | 자동으로 노이즈 처리 → 실루엣 점수 폭등 |
| 데이터 규모 | 100만 건도 5초 | 5만 건 이하면 OK, 10만 건 넘으면 느림 | 100만 건도 OK (HDBSCAN은 10만 건 추천) |
| 실루엣 점수 평균 | 0.40~0.65 | 0.50~0.75 | 0.65~0.90 (실무 최고) |
| 비즈니스팀 반응? | 그냥 5개 그룹 줘라 | 우리가 직접 자를게 → 덴드로그램 사랑 | 이상치까지 깔끔하게 정리돼서 굿 |
| 2025년 실무 점유율 | 45% (대량 단순 세그먼트) | 20% (VIP·프리미엄 고객 분석) | 35% (실제 데이터 = 이상치 많음) |
| PM이 사용해야 하는 상황 | • 고객 50만 명 이상 • 속도 제일 중요 • 평균값으로 해석 필요 |
• 고객 5만 명 이하 • 마케팅팀이 그룹 수 조정 원함 • 계층 구조 필요 |
• 실루엣 점수 0.5 이하일 때 • 이상치·노이즈 많을 때 • 모양이 동그랗지 않을 때 |
평가 지표

- 엘보우 방법(elbow method): K 를 1개~15개까지 돌려보고 SSE(오차의 제곱합)이 급격히 줄어들다가, 더 이상 줄어들지 않는 그래프상의 '팔꿈치 지점' 을 최적의 K 로 선택하는 방법.
| K(옷장의 칸막이 수) | 정리된 정도(SSE) |
| K=1 (칸막이 없음) | 옷 전부 한 덩어리 → 엄청 어질러짐 (SSE 1000) |
| K=3 | 꽤 깔끔해짐 → SSE 급격히 감소 (300) |
| K=6 | 조금 더 깔끔해지긴 하지만 큰 차이가 없음 (180) |
| K=10 | 거의 똑같은데 칸막이만 늘어남 (150) → 여기서부터 '과잉 정리' |

- 실루엣 점수(silhouette score): 내가 속한 그룹에서 내 위치가 얼마나 가까운지(a), 다른 그룹과는 얼마나 먼지(b)를 비교해서, -1부터 +1 사이의 숫자로 클러스터링 품질을 알려주는 지표. 0.55 이상이면 클러스터링 품질이 좋다고 봅니다.
- 하나의 데이터 i에 대한 실루엣 점수 s(i) 계산방법
- s(i) = (b(i) − a(i)) / max(a(i), b(i)) → −1 ≤ s(i) ≤ +1
- a(i): 내가 속한 클러스터 안의 모든 점들과의 거리 평균.
- b(i): 나와 가장 가까운 다른 클러스터의 모든 점들과의 거리 평균.
| 실루엣 점수 | 비유 | 의미 |
| +0.7 ~ +1.0 | “완전 딱 맞는 테이블! 친구들끼리만 죽이 척척” | 최고의 클러스터링 |
| +0.5 ~ +0.7 | “우리 테이블 분위기 좋고, 옆 테이블도 좀 끌리긴 하지만 그래도 여기가 맞아” | 실무에서 충분히 좋은 수준 (목표) |
| +0.3 ~ +0.5 | “우리 테이블 나쁘진 않은데, 저쪽 테이블이 더 재밌어 보이기도…” | 보통 이하 → K 다시 조정 |
| 0 근처 | “여기 앉아도 별 차이 없네…” | 클러스터링이 거의 의미없음 |
| 음수 | “여기 앉으면 안 되는데… 저쪽이 훨씬 나은데?” | 잘못된 클러스터링 |
사례/예시
- Amazon의 e-commerce 플랫폼에서 K-means 클러스터링은 레이블 없는 구매 데이터를 그룹화해 '프리미엄 쇼퍼'와 '가격 민감형' 클러스터를 발견하며, 이를 지도학습(추천 모델)의 입력으로 사용해 전환율을 25% 높였습니다.
- Pfizer의 유전자 데이터 분석에서 계층적 클러스터링을 통해 환자 그룹을 분류, 약물 개발 타겟을 식별해 R&D 비용을 35% 절감했습니다.
- 파티 손님 그룹화
- 지도학습은 호스트가 "이 사람은 엔지니어, 저 사람은 마케터"처럼 미리 라벨을 붙여 그룹화하는 반면, 클러스터링은 손님들의 대화 주제나 취향만 보고 자연스럽게 '테크 토커 클러스터'와 '푸드 토커 클러스터'를 형성합니다.
- 그러나 클러스터 수가 과도하면(과적합) 그룹이 너무 세분화되어 해석이 어려워지므로, 비즈니스 목표에 맞는 K 값 선택이 핵심입니다.
반응형
'AI Study > 머신러닝(ML)' 카테고리의 다른 글
| 머신러닝의 기초: 대비 학습(Contrastive Learning) (1) | 2025.11.27 |
|---|---|
| 머신러닝의 기초: 생성적 적대 신경망(Generative Adversarial Networks; GAN) (3) | 2025.11.26 |
| 머신러닝의 기초: 신경망(Neural Network) (1) | 2025.11.24 |
| 머신러닝의 기초: SVM(Support Vector Machine) (0) | 2025.11.22 |
| 머신러닝의 기초: 랜덤 포레스트(Random Forest) (1) | 2025.11.21 |